
GRAPPA: Generalizing and Adapting Robot Policies via Online Agentic Guidance
Arthur Bucker, Pablo Ortega-Kral, Jonathan Francis, Jean Oh
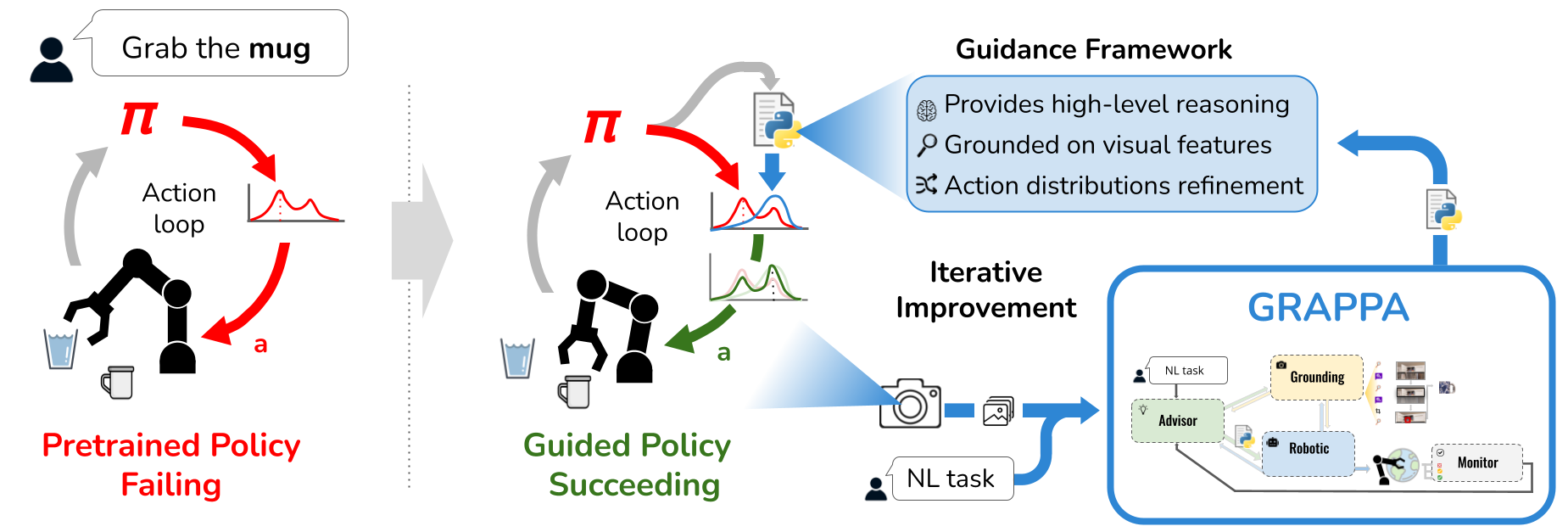
Robot learning approaches such as behavior cloning and reinforcement learning have shown great promise in synthesizing robot skills from human demonstrations in specific environments. However, these approaches often struggle to generalize to unseen real-world settings because they rely on task-specific demonstrations or complex simulators. While foundation models (e.g., LLMs, VLMs) offer rich semantic understanding from internet-scale data, using this knowledge to enable robotic systems to understand the underlying dynamics of the world, generalize policies across different tasks, and adapt policies to new environments remains an open challenge. To alleviate these limitations, we propose an agentic framework for robot self-guidance and self-improvement that comprises a set of role-specialized conversational agents, including a high-level advisor, a grounding agent, a monitoring agent, and a robotic agent. Our framework iteratively grounds a base robot policy on relevant objects in the environment and uses visuomotor cues to shift the policy’s action distribution toward more desirable states online, while remaining agnostic to the subjective configuration of a given robot hardware platform. We demonstrate that our approach can effectively guide manipulation policies to achieve significantly higher success rates, both in simulation and in real-world experiments, without the need for additional human demonstrations or extensive exploration. Code and videos are available at: https://agenticrobots.github.io/